この記事でわかること
- Titans論文の提案手法と3つの構成バリアントの違い
- Transformerが抱えていた長文コンテキスト課題
- 論文が示した実験結果の読み方と注意点
- 中小企業のAI導入判断にどう使えるか
- 既存LLMとの併用判断の論点
3つの要点
- Titansは、Transformerに「テスト時に学習する長期記憶モジュール」を組み込む新アーキテクチャを提案しています(論文: arXiv:2501.00663、Ali Behrouz、Peilin Zhong、Vahab Mirrokni、Google Research、2024年12月31日公開)
- 論文では2Mトークンを超える長文コンテキストでも、同サイズのTransformerより精度を維持できると報告しています
- 大規模事前学習モデルの公開は限定的で、実務導入は「研究を理解して既存LLMの代替候補として評価する」段階です
長文コンテキストを扱う系列モデルは、すでに複数の課題が指摘されてきました。
- 計算量がコンテキスト長の2乗で増えるため、長文処理のコストが急増する
- 中間情報が無視されやすく、長文での精度劣化が起きやすい(lost in the middle)
- 線形時間で動くMambaなどの代替系列モデルは、長期依存の記憶が弱いと指摘されている
背景
Titans論文は「Transformerの短期注意」と「線形系列モデルの効率」を別軸として捉え、両者を補完する長期記憶モジュールを設計するという立場を取っています。
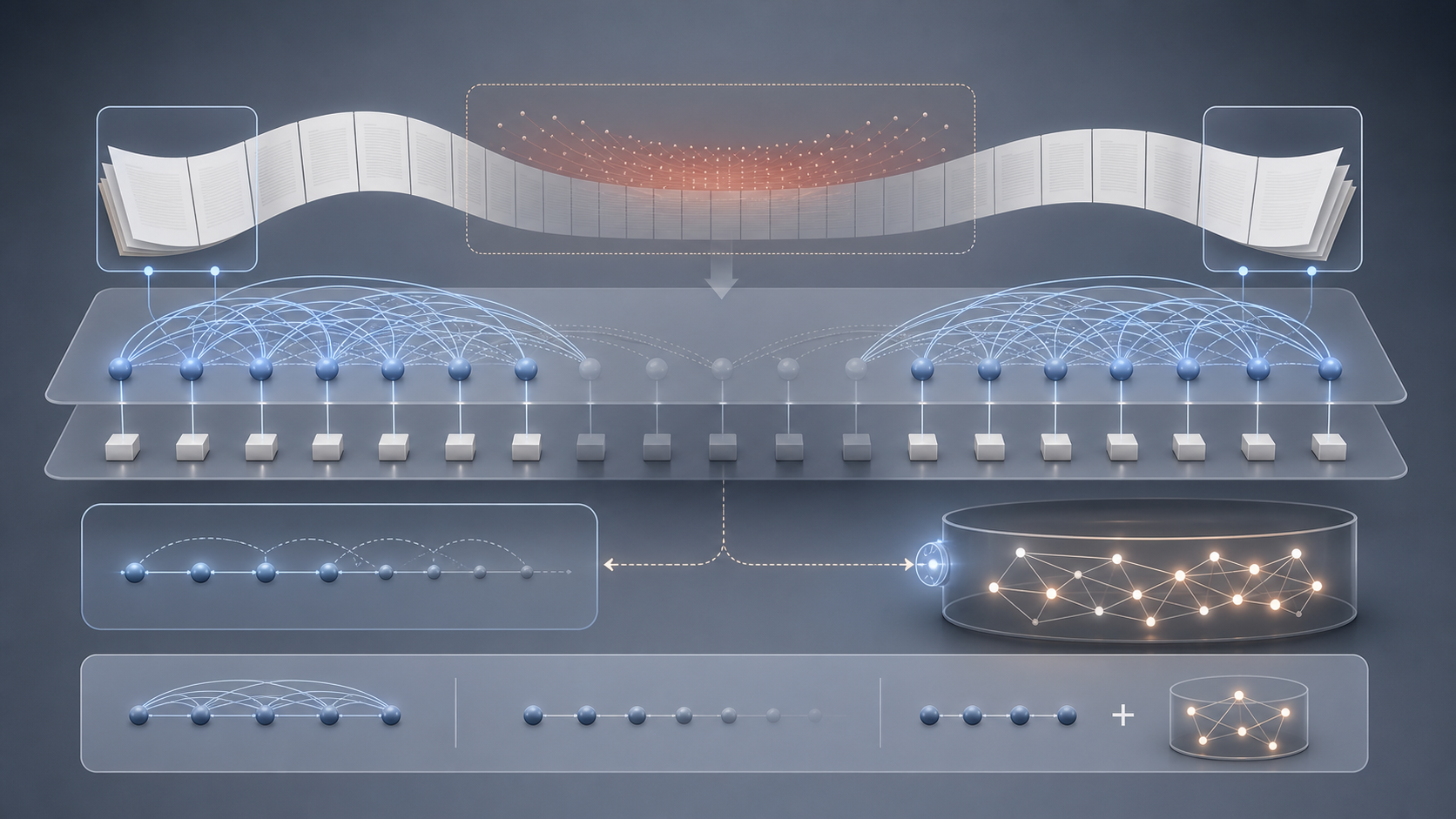
Titansが提案する仕組み
論文の提案を3つの段階で読むと理解しやすくなります。
直感:何をどう変えたのか
Titansは、コンテキスト全体を一度に注意で処理するのではなく、長期記憶モジュールにテスト時の学習をさせて、過去情報を圧縮しながら保持する設計です。
「驚き信号(surprise)」を使って、予測しにくかった入力ほど強くメモリに刻む点が特徴です。人間が印象的な出来事を長く覚える挙動に近い発想として説明されています。
技術要点:どこを変えたのか
- メモリは入力から鍵・値・クエリを取り出し、テスト時に勾配でメモリパラメータを更新する
- 過去の更新も考慮するモメンタム項、不要記憶を忘れる重み減衰項を持つ
- 短期注意モジュールと長期メモリを組み合わせるため、3つの構成を提示している
論文では3構成を次のように整理しています。
| 構成 |
統合位置 |
特徴 |
| MAC(Memory as Context) |
メモリ出力をコンテキストに連結 |
既存Transformerに近い使い方ができる |
| MAG(Memory as Gate) |
メモリ経路と注意経路をゲートで合成 |
経路を動的に切り替えやすい |
| MAL(Memory as a Layer) |
レイヤーの一部にメモリを置換 |
線形時間で動かしやすい構造 |
実務上の意味:どこに効くのか
- 長文書を一度に読ませる用途で、コスト増を抑えながら精度を維持しやすい
- 「過去の重要な箇所だけを圧縮して残す」挙動を、外部RAGとは別レイヤーで実現できる
- アーキテクチャ自体に長期記憶があるため、エージェント記憶の設計負荷を一部減らせる
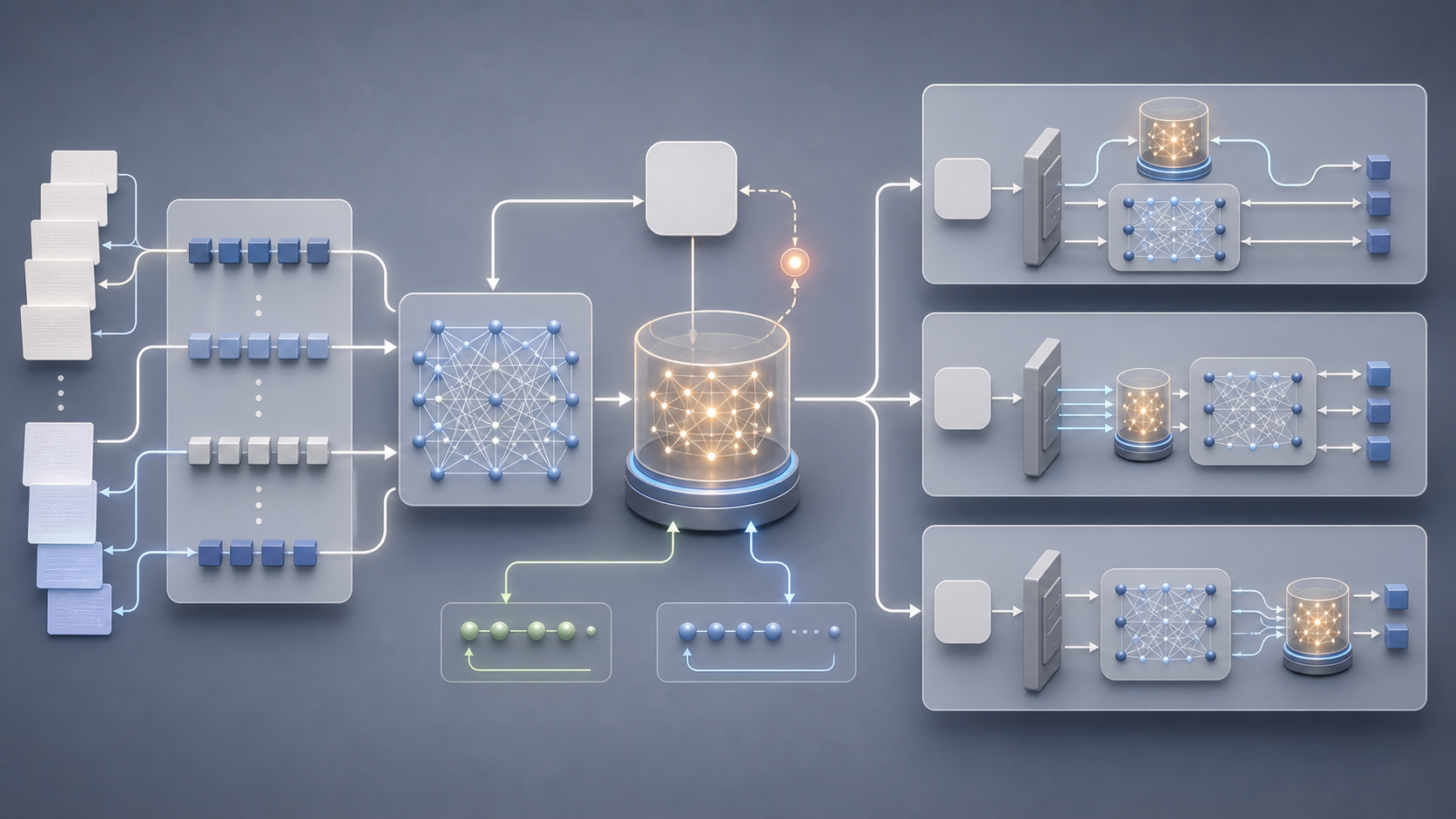
実験結果の読み方
論文では複数のベンチマークで評価が行われており、主な観点は次の通りです。

| 比較軸 |
従来手法(例) |
Titans系 |
実務上の読み方 |
| 長文言語モデリング |
Transformer、Mamba系 |
同サイズで精度優位を主張 |
長文書要約・解析の精度を底上げできる可能性 |
| Needle-in-Haystack |
長文での検索精度が低下しやすい |
長文でも高精度を維持と報告 |
規程・契約書からの該当箇所抽出に向くか評価する価値あり |
| BABILong(長文推論) |
長文での性能差が大きい |
既存大規模モデルを上回るケースを報告 |
業務文書の多段推論にどこまで耐えるか要検証 |
| コンテキスト長 |
数十万〜100万トークンが中心 |
2M超でも精度を維持と報告 |
長期ログ・コール履歴の一括分析の選択肢になり得る |
数値の扱い
各ベンチマークの具体的なスコアは論文本文で確認してください。記事内では、論文が報告した相対的な優位の方向性のみを参照しています。
〖注意喚起〗限界と未検証の領域
Titans論文は、企業導入の前提を満たすには情報が不足している領域もあります。

- 大規模事前学習済みモデルが広く公開されていないため、すぐに本番利用できる前提ではない
- ハイパーパラメータの選び方が性能に影響しやすく、社内検証なしの導入は危険
- 多言語、日本語特有のトークン分割での性能は論文だけでは判断しきれない
- 既存のLLMサービング基盤(vLLM、TGIなど)との統合知見が薄い
注意
「Transformerより優れた」という見出しだけで導入判断はできません。論文の実験条件、評価データ、モデル規模を確認したうえで、自社業務との距離を測ることが必要です。
実務への示唆:中小企業はどう向き合うか
Titansを今すぐ採用する必要はありません。ただし、長文コンテキストを使う設計判断には影響します。長文書処理や社内ナレッジ統合のためにLLM選定を続けている担当者、エージェント記憶設計を検討している開発リードには論点が直結します。

- 長文書処理の精度に課題がある場合、現行のLLM選定だけでなくアーキテクチャ側の進化も評価対象に入れる
- RAGとモデル内記憶は補完関係にあるため、「外部検索 + モデル内圧縮記憶」の二重設計を視野に入れる
- エージェント記憶設計(0030で扱ったサーベイ視点)と、モデル本体の長期記憶設計を分けて議論する
- 既存ベンダーのロードマップで、テスト時学習や長期記憶モジュールが言及され始めたら、選定基準に組み込む
実務適用前のチェックリスト
- 業務文書の平均長と最大長を計測しているか
- 現行LLMで「中間が無視される」「長文ほど精度が落ちる」事象が出ていないか
- 長期文脈が必要な業務と、短期問い合わせ業務を切り分けているか
- モデル変更時に評価できる業務ベンチマークを社内で持っているか
- ベンダーロックインを避けるためのデータ抽象化が進んでいるか
Blackfordの見解
Titans論文は「モデル本体に長期記憶を持たせる」という方向性を強く示しました。中小企業の現場では、まだ研究段階として位置づけるのが妥当です。
一方で、社内ナレッジ活用や長文書処理を本格化させるなら、論文が示した3つの論点は実務にも有効です。
- 長文コンテキストを「使えるサイズ」と「使い切れるサイズ」に分けて評価する
- メモリ機構を「外部RAG」「エージェント記憶」「モデル内記憶」の3層で整理する
- アーキテクチャ進化を、業務文書の量・長さ・更新頻度の観点から監視する
社内ナレッジ統合や長文書解析の運用設計が必要な場合は、データ基盤側で対応できる範囲も大きく残っています。DataRoidは、業務データの統合と長文書活用の足場を整えるサービスです。研究の成熟を待つ前にできる選択肢として、論文の評価軸を業務文書の量・長さ・更新頻度に置き換えて検討する初手にも向きます。
よくある質問
Titansは今すぐ業務利用できますか
業務利用の標準にはまだ早い段階です。論文時点では事前学習済みモデルの広い公開がなく、社内検証のハードルが高いためです。長文書処理に課題があるなら、まず既存LLMの長文コンテキスト性能評価を進めるのが現実的です。
短期間で完全に置き換える可能性は低いと考えます。論文は「補完設計」を強調しており、注意機構を捨てる主張ではありません。長期記憶を補う方向の研究として、長期視点でウォッチする領域です。
RAGの代わりになりますか
部分的に補完しますが、置き換えにはなりません。RAGは外部検索による情報の最新化と監査性が強みです。Titansが扱うのはモデル内部での圧縮記憶のため、両者は並立する設計判断として扱うのが妥当です。
日本語の長文書でも有効ですか
論文だけで断定できません。ベンチマークは主に英語ベースのため、日本語固有のトークン化や語順の特性を含めた検証は別途必要です。導入を検討する場合は、社内文書での小規模検証を前提にしてください。
まとめ
Titansは、Transformerに長期記憶モジュールを統合する有力な研究で、長文コンテキスト時代のアーキテクチャ進化を象徴する1本です。ただし、現時点では事前学習済みモデルや実装知見が限定的で、実務導入は研究フェーズの位置づけが妥当です。
長文書処理や社内ナレッジ活用の課題が顕在化しているなら、外部RAG、エージェント記憶、モデル本体の進化を分けて整理することが先決です。自社業務での影響を判断したい場合は、現行データの構造化や長文書の評価設計から進めるのが現実的な一歩になります。
Blackfordに相談する






